


















































 更新时间:2024-12-29 20:04:32
更新时间:2024-12-29 20:04:32 建站经验
建站经验 476
476缓存失效情况举例
看下这个段伪代码:
local value = get_from_cache(key)
if not value then
value = query_db(sql)
set_to_cache(value, timeout = 100)
end
return value
看上去没有问题,在单元测试情况下,也不会有异常。
但是,进行压力测试的时候,你会发现,每隔100秒,数据库的查询就会出现一次峰值。如果你的cache失效时间设置的比较长,那么这个问题被发现的机率就会降低。
为什么会出现峰值呢?想象一下,在cache失效的瞬间,如果并发请求有1000条同时到了 query_db(sql) 这个函数会怎样?没错,会有1000个请求打向数据库。这就是缓存失效瞬间引起的风暴。它有一个英文名,叫 "dog-pile effect"。
怎么解决?自然的想法是发现缓存失效后,加一把锁来控制数据库的请求。具体的细节,春哥在lua-resty-lock的文档里面做了详细的说明,我就不重复了,请看这里。多说一句,lua-resty-lock库本身已经替你完成了wait for lock的过程,看代码的时候需要注意下这个细节。
传统缓存失效应对策略 为了提高业务访问速度,提升业务读并发,很多用户都会在业务架构中引入缓存层。业务所有读请求全部路由到缓存层,通过缓存的内存读取机制大大提升业务读取性能。缓存中的数据不能持久化 ,一旦缓存异常退出,那么内存中的数据就会丢失,所以为了保证数据完整,业务的更新数据会落地到持久化存储中,例如DB。目前云用户的业务架构一般如下图:
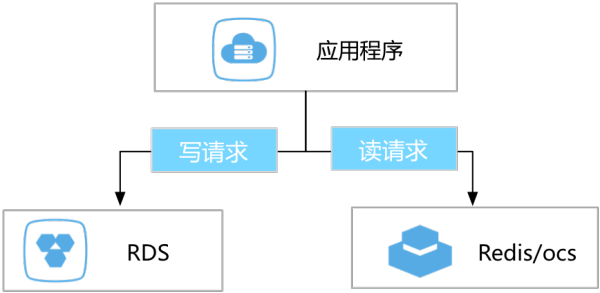
在上图中,大家可以看到,用户的更新数据直接持久化到DB, 业务读请求直接请求缓存数据,所以业务需要解决缓存失效问题,即解决因为数据变更导致缓存中的数据失效的问题。 目前业务解决缓存失效问题的解决方法一般是业务实现DB、缓存双写。通过业务双写解决缓存失效,存在如下的问题:
代码侵入性比较强,需要双写两份存储,任何对DB的数据变更,都需要同时更新缓存,代码层面后期可维护程度不高
用户请求线程里同步调用缓存,对缓存存在强以来,遇到缓存超时等异常时,没有办法做到有效的重试,遇到异常给用户返回系统错误、操作失败等信息,严重影响用户体验
用户请求线程里同步完成DB、缓存双写,变更请求链路长,访问延迟大,影响用户体验
RDS数据订阅消费,轻松解决缓存失效
在阿里巴巴内部同样也遇到了缓存失效的问题,随着业务架构得不断调整优化,我们已经沉淀出一套高可靠、极优雅得缓存失效架构。即通过数据传输提供的数据订阅功能,异步获取DB(例如公共云上的RDS)的增量数据,根据增量数据进行缓存失效。具体的架构类似下图:
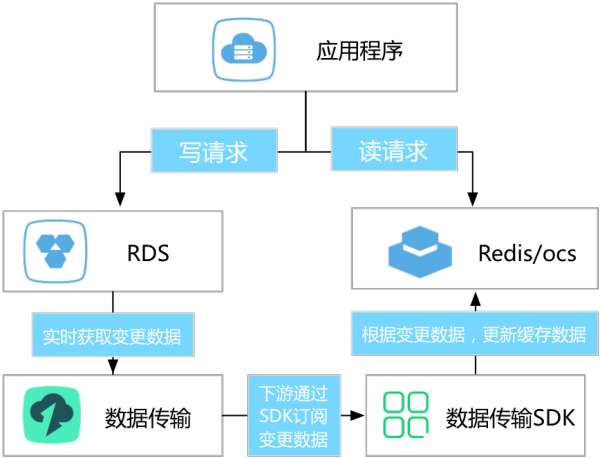
在这个架构里面,缓存更新流程如下:
1.业务完成DB更新后即返回请求
2.数据订阅通过日志解析方式实时解析并订阅DB的增量更新数据,当发现DB有数据更新时,将增量数据推送给下游消费者
3.下游消费业务一旦接收到增量更新数据,即调用消费线程进行缓存更新
至此完成整个缓存更新过程。
从上面的缓存失效流程,可以看出这种缓存失效机制:
1.更新路径短,延迟低: 缓存失效为异步流程,业务更新DB完成后直接返回,不需要关心缓存失效流程,整个更新路径短,更新延迟低
2.应用简单可靠:应用无需实现复杂双写逻辑,只需启动异步线程监听增量数据,更新缓存数据即可
3.应用更新无性能消耗:因为数据订阅是通过解析DB的增量日志来获取增量数据,获取数据的过程对业务、DB性能无损
小结 数据订阅功能为阿里云数据传输提供的一种数据分发方式。通过数据订阅实现的缓存失效策略,让业务更新更快捷,让业务逻辑更简单、更可靠。
数据订阅只是数据传输提供的一种传输方式,除数据订阅之外,数据传输还提供了数据实时同步,不停服迁移等多种传输能力,如需了解数据传输更多详情,请猛击数据传输。
我们专注高端建站,小程序开发、软件系统定制开发、BUG修复、物联网开发、各类API接口对接开发等。十余年开发经验,每一个项目承诺做到满意为止,多一次对比,一定让您多一份收获!










